
NumPy is an open source package (i.e. extension library) for the Python programming language originally developed by Travis Oliphant. It primarily provides
N-dimensional array data structures (some might call these tensors...) well suited for numeric computation.
Sophisticaed "broadcasting" operations to allow efficient application of mathematical functions and operators over entire arrays of data, e.g. calling
sin(x)an NumPy arrayxreturns the element-wise sine of the numbers contained inx.
If you've heard that Python is slow for numerical computations, it's primarily due to "duck typing". Duck typing is a colloquial phrase that refers to the fact that in Python, we don't declare variable types (e.g. string, float, int, etc.) when we declare variables. They are inferred at runtime. In summary,
Duck Typing:
- If it looks like a duck, then it is a duck.
- a.k.a. dynamic typing
- Dynamic typing requires lots of metadata around a variable.
This causes runtime overhead leading to poor performance in numerical computations.
Solution: NumPy data structures
- Data structures, as objects, that have a single type and contiguous storage.
- Common functionality with implementation in C.
Contiguous storage means that the array data is stored in a continuous "chunk" in memory, i.e. the elements of an array are next to each other in memory in the order they appear in the array. This adds performance by avoiding "cache misses" and other low-level performance issues.
Most NumPy operations can be expected to perform at a level very-close to what you would expect from compiled C code.
The fact that NumPy arrays are objects makes them slightly different that arrays in C code. NumPy arrays have attributes that can be changed and queried, e.g. the shape or data type of an array.
To demonstrate the efficacy of NumPy, we'll perform the same operation, i.e. adding 1 to an array containing a million numbers, using a Python list comprehension and then using a NumPy array.
We use the %timeit magic function from IPython which runs the command that follows it a number of times and reports some statistics on how long it takes the function to execute. First, the Python list comprehension
%timeit [i+1 for i in range(1000000)]
And now the NumPy equivalent
Here the + 1 is broadcast across the array, i.e. each element has 1 added to it.
import numpy as np
%timeit np.arange(1000000) + 1
Here we see that adding 1 to a million numbers in NumPy is significantly faster than using a Python list comprehension (which itself is much faster than a for loop would be in pure Python).
import math
%timeit [math.sin(i) ** 2 for i in range(1000000)]
%timeit np.sin(np.arange(1000000)) ** 2
It's idiomatic to import NumPy with the statement
import numpy as np
and use the abbreviated np namespace.
import numpy as np
x = np.array([2,3,11])
x = np.array([[1,2.],[0,0],[1+1j,2.]])
x = np.arange(-10,10,2, dtype=float)
x = np.linspace(1.,4.,6)
x = np.fromfile('foo.dat')
NumPy arrays can be created from regular Python lists of floats, integers, strings, etc. and the types will be infered. However, it's also possible (and not a bad idea to enhance readability/clarity) to specify the data-type explicitly using the optional keyword dtype. There are several other ways to create arrays from arange, linspace, etc.
import numpy as np
x = np.arange(9).reshape(3,3)
x
Here we create a one-dimensional array with the np.arange() function that containts the integer numbers 0-9. Then we reshape it to be a 3 x 3 array. Keep in mind that the memory is still continguous and the reshape operation merely offers a different 'view' of the data. It also allows us to use multiple indexes and special notation to retrieve parts of the data, e.g.
x[:,0]
An explanation of the notation used in the operation above: the comma (,) separates dimensions of the array in the indexing operation. The colon (:) represents all of that dimension. So is this operation, the colon signifies getting all rows, i.e. the $0^\mbox{th}$ dimension of the array. Along the second dimension, i.e. the columns, the 0 represents the $0^\mbox{th}$ indexed column.
Getting parts of array with this type of notation is called slicing in NumPy.
x.shape
shape is an attribute of the x NumPy array object. We can see that it has been changed from what would have been originally (9,) before the reshape() class method was called.
Here is another, more sophisticated slicing operation.
y = x[::2, ::2]
y
The equivalent and more explicit syntax for this slicing operation might read:
y = x[0:-1:2,0:-1:2]
The first 0:-1 gets the $0^\mbox{th}$ entry through the last entry (-1 index) along the $0^\mbox{th}$ dimesion, i.e. all rows. The final :2 indicates the increment, i.e. get every $2^\mbox{nd}$ entry along the dimension.
It's possible to use indexing to specify a single entry in an array, e.g.
y[0,0] = 100
y
x
Note that this operation also changes the value of the (0,0) entry in the original array.
x[0,0]
This is because the operation
y = x[::2, ::2]
is only a shallow copy or "view" to that portion of x. If you wanted to make an actual copy of the data contained in x into y, use the copy() method.
y = x[::2, ::2].copy()
y[0,0] = 200
print("x = \n\n {}\n".format(x))
print("y = \n\n {}".format(y))
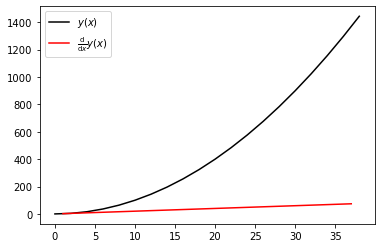
A common approximation for computing derivatives of functions is a finite difference approximation
$$ \frac{\mathrm{d}}{\mathrm{d}x}y(x) \approx \frac{y(x + \Delta x) - y(x)}{\Delta x} $$or for discrete data
$$ \frac{\mathrm{d}}{\mathrm{d}x}y(x_i) \approx \frac{y(x_i + \Delta x_{i+1/2}) - y(x_i)}{\Delta x_{i+1/2}} $$where $\Delta x_{i + 1/2} = x_{i+1} - x_{i}$. This operation can be accomplished efficiently and compactly using NumPy's slicing and vectorized algebraic operations.
x = np.arange(0,40,2)
y = x ** 2
dy_dx = (y[1:] - y[:-1]) / (x[1:] - x[:-1]); dy_dx
A plot showing the derivative of the quadratic curve is a straight line as expected.
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(x, y, 'k-', label=r'$y(x)$')
plt.plot((x[1:] + x[:-1]) / 2, dy_dx, 'r-', label=r'$\frac{\mathrm{d}}{\mathrm{d}x} y(x)$')
plt.legend();
Broadcasting is a term that is used when performing arithmetic operations on arrays of different shapes. The example of adding 1 to an array with one million entries shown earlier was a simple example of broadcasting. A more complex operation is shown below.
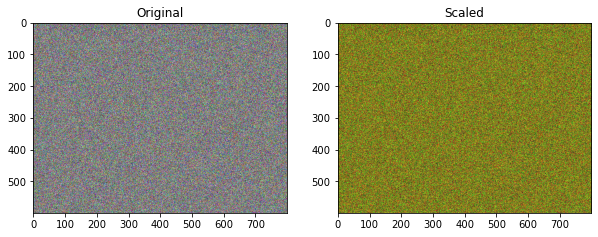
First we create 3 arrays, each with 800 rows and 600 columns of random numbers. Then we combine these arrays into a multidimensional array with the shape (3, 800, 600). Transposing this array gives us an 600 by 800 array (possibly representing individual pixels in an image), with each entry containing a three entris (possibly representing the RGB color definition of that pixel).
red = np.random.rand(800,600)
blue = np.random.rand(800, 600)
green = np.random.rand(800, 600)
rgb = np.array([red, blue, green])
rgb.shape
We can scale the RGB values by half for each pixel by multiplying by another, smaller array. This smaller array is broadcast accross the transpose of the rbg array along the trailing dimension.
rgb.T * np.array([0.5, 0.5, 0.25])
Of course the arrays are quite large so inspecting the individual numbers is difficult. Below are the two arrays plotted as images.
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(1,2, figsize=(10,12) )
ax[0].imshow(rgb.T);
ax[0].set_title('Original');
ax[1].imshow(rgb.T * np.array([1., 1., 0.25]));
ax[1].set_title('Scaled');
Fancy indexing is special syntax, specific to NumPy, that allows for extracting parts of arrays. Starting with an array x
x = np.arange(9); x
We saw earlier that you can select indiviual parts of arrays using indexing. The following selects and returns the 4th entry of the array x cooresponding to the index 3.
x[3]
This functionality is extended by giving a list of indices. The following selects the first, forth, and last (-1 index) entries in the array x.
x[[0,3,-1]]
xx = [1 ,3, 5, 7]
xx[[2,3]]
Fancy indexing can also be used in multple dimensions.
y = x.reshape((3,3)); y
Now using the 0 index returns the entire first row.
y[0]
Providing a list along the first dimension returns the entire second and third rows.
y[[1,2]]
A more complicated example where entries along each dimension are provided in a tuple. This can be interpreted as requesting the $(0,0), (1,1),$ and $(2,0)$ entries.
y[([0,1,2],[0,1,0])]
Booleen arrays can be combined with fancy indexing to provide a powerful way to do advanced data manipulation and cleaning. We'll start by created a random array of integers selected between -10 and 10.
x = np.random.randint(-10, 10, 10); x
We can use a broadcasted booleen operation to create a booleen array as follows. In this case, everywhere in the array that the entry is greater than zero we get a True, and a False otherwise.
ind = x > 0; ind
Now we can use this booleen array to return only the values of x that are greater than zero.
x[ind]
The NumPy where() function gives a powerful way to do selective data manipulation. E.g. we can set the any values of the array x that are negative to np.nan.
y = np.where(ind, x, 0); y
Further Reading
Further reading on NumPy is avialable in the official NumPy documentation.